このページは、まだ日本語ではご利用いただけません。翻訳中です。
Explorer
Explorer is an intuitive web-based interface that displays API usage data gathered by Konnect Analytics from your data plane nodes. You can use this tool to promptly diagnose performance issues, monitor LLM token consumption and costs, or capture essential usage metrics. Explorer also provides the option to save the output as custom reports. You can access the Explorer from any Advanced Analytics chart by clicking through the context (kebab) menu.

To begin using Explorer, go to the Analytics  section and select Explorer. You can select from API Usage or LLM Usage from the dashboard options.
section and select Explorer. You can select from API Usage or LLM Usage from the dashboard options.
API usage reporting
Grouping and Filtering
Metrics
Time intervals
- API Product
- API Product Version
- Application
- Consumer
- Control Plane
- Control Plane Group
- Data Plane Node
- Data Plane Node Version
- Gateway Services
- None
- Response Source
- Route
- Status Code
- Status Code Group
- Upstream Status Code
- Upstream Status Code Group
Traffic metrics provide insight into which of your services are being used and how they are responding. Within a single report, you have the flexibility to choose one or multiple metrics from the same category.
| Metric |
Category |
Description |
| Request Count |
Count |
Total number of API calls within the selected time frame. This includes requests that were rejected due to rate limiting, failed authentication, and so on. |
| Requests per Minute |
Rate |
Number of API calls per minute within the selected time frame. |
| Response Latency |
Latency |
The amount of time, in milliseconds, that it takes to process an API request. Users can select between average (avg) or different percentiles (p99, p95, and p50). For example, a 99th percentile response latency of 10 milliseconds means that every 1 in 100 requests took at least 10 milliseconds from request received until response returned. |
| Upstream Latency |
Latency |
The amount of time, in milliseconds, that Kong Gateway was waiting for the first byte of the upstream service response. Users can select between different percentiles (p99, p95, and p50). For example, a 99th percentile response latency of 10 milliseconds means that every 1 in 100 requests took at least 10 milliseconds from sending the request to the upstream service until the response returned. |
| Kong latency |
Latency |
The amount of time, in milliseconds, that Kong Gateway was waiting for the first byte of the upstream service response. Users can select between different percentiles (p99, p95, and p50). For example, a 99th percentile response latency of 10 milliseconds means that every 1 in 100 requests took at least 10 milliseconds from the time the Kong Gateway received the request up to when it sends it back to the upstream service. |
| Request Size |
Size |
The size of the request payload received from the client, in bytes. Users can select between the total sum or different percentiles (p99, p95, and p50). For example, a 99th percentile request size of 100 bytes means that the payload size for every 1 in 100 requests was at least 100 bytes. |
| Response Size |
Size |
The size of the response payload returned to the client, in bytes. Users can select between the total sum or different percentiles (p99, p95, and p50). For example, a 99th percentile response size of 100 bytes means that the payload size for every 1 in 100 response back to the original caller was at least 100 bytes. |
The time frame selector controls the time frame of data visualized, which indirectly controls the
granularity of the data. For example, the “5M” selection displays five minutes in
one-second resolution data, while longer time frames display minute, hour, or days resolution data.
All time interval presets are relative. This means that time frames are dynamic and the report captures a snapshot of data
relative to when a user views the report.
For custom reports, you can also choose a custom date range. Custom means that time frames are static and the report captures a snapshot of data
during the specified time frame. You can see the exact range below
the time frame selector. For example:
Jan 26, 2023 12:00 AM - Feb 01, 2023 12:00 AM (PST)
| Interval |
Description |
| Last 15 minutes |
Data is aggregated in one minute increments. |
| Last hour |
Data is aggregated in one minute increments. |
| Last six hours |
Data is aggregated in one minute increments. |
| Last 12 hours |
Data is aggregated in one hour increments. |
| Last 24 hours |
Data is aggregated in one hour increments. |
| Last seven days |
Data is aggregated in one hour increments. |
| Last 30 days |
Data is aggregated in daily increments. |
| Current week |
Data is aggregated in one hour increments. Logs any traffic in the current calendar week. |
| Current month |
Data is aggregated in one hour increments. Logs any traffic in the current calendar month. |
| Previous week |
Data is aggregated in one hour increments. Logs any traffic in the previous calendar week. |
| Previous month |
Data is aggregated in daily increments. Logs any traffic in the previous calendar month. |
System defined groups
-
Empty - Empty is a system-defined group that indicates that API calls do not have an entity like consumers or routes, selected for grouping. Empty allows you to group API calls that don’t match specific groupings so you can gain more comprehensive insights.
Empty can be used in cases like this:
- Identify the number of API calls that don’t match a route.
- Identify API calls without an associated consumer to keep track of any security holes.
Empty is displayed in italics in Konnect, and it is not mandatory, using Is Empty or Is Not Empty, you can filter results in Explorer.
LLM usage reporting
Advanced Analytics allows you to monitor and optimize your LLM usage by providing detailed insights into objects such as token consumption, costs, and latency.
With LLM usage reporting, you can:
- Track token consumption: Monitor the number of tokens processed by the different LLM models you have configured.
- Understand costs: Gain visibility into the costs associated with your LLM providers.
- Measure Latency: Analyze the latency involved in processing LLM requests.
To use this feature, navigate to the Explorer dashboard and switch between API usage and LLM usage using the new dataset dropdown. Metrics and groupings will dynamically adjust based on the selected dataset.
Note: LLM usage reporting requires at least Kong Gateway version 3.8.
Grouping and Filtering
Metrics
Time intervals
- Application
- Cache Status
- Consumer
- Control Plane
- Control Plane Group
- Embeddings Model
- Embeddings Provider
- Provider
- Request Model
- Response Model
- Route
Traffic metrics provide insight into which of your services are being used and how they are responding. Within a single report, you have the flexibility to choose one or multiple metrics from the same category.
| Attribute |
Unit |
Description |
| Completion Tokens |
Count |
Completion tokens are any tokens that the model generates in response to an input. |
| Prompt Tokens |
Count |
Prompt tokens are the tokens input into the model. |
| Total Tokens |
Count |
Sum of all tokens used in a single request to the model. It includes both the tokens in the input (prompt) and the tokens generated by the model (completion). |
| Time per Tokens |
Number |
Average time in milliseconds to generate a token. Calculated as LLM latency divided by the number of tokens. |
| Costs |
Cost |
Represents the resulting costs for a request. Final costs = (total number of prompt tokens × input cost per token) + (total number of completion tokens × output cost per token) + (total number of prompt tokens × embedding cost per token). |
| Response Model |
String |
Represents which AI model was used to process the prompt by the AI provider. |
| Request Model |
String |
Represents which AI model was used to process the prompt. |
| Provider Name |
String |
Represents which AI provider was used to process the prompt. |
| Plugin ID |
String |
Represents the UUID of the plugin configuration. |
| LLM Latency |
Latency |
Total time taken to receive a full response after a request sent from Kong (LLM latency + connection time). |
| Embeddings Latency |
Latency |
Time taken to generate the vector for the prompt string. |
| Fetch Latency |
Latency |
Total time taken to return a cache. |
| Cache Status |
String |
Shows if the response comes directly from the upstream or not. Possible values: hit or Miss. |
| Embeddings Model |
String |
AI providers may have multiple embedding models. This represents the model used for the embeddings. |
| Embeddings Provider |
String |
Provider used for generating embeddings. |
| Embeddings Token |
Count |
Tokens input into the model for embeddings. |
| Embeddings Cost |
Cost |
Cost of caching. |
| Cost Savings |
Cost |
Cost savings from cache. |
The time frame selector controls the time frame of data visualized, which indirectly controls the
granularity of the data. For example, the “5M” selection displays five minutes in
one-second resolution data, while longer time frames display minute, hour, or days resolution data.
All time interval presets are relative.
For custom reports, you can also choose a custom date range.
| Interval |
Description |
| Last 15 minutes |
Data is aggregated in one minute increments. |
| Last hour |
Data is aggregated in one minute increments. |
| Last six hours |
Data is aggregated in one minute increments. |
| Last 12 hours |
Data is aggregated in one hour increments. |
| Last 24 hours |
Data is aggregated in one hour increments. |
| Last seven days |
Data is aggregated in one hour increments. |
| Last 30 days |
Data is aggregated in daily increments. |
| Current week |
Data is aggregated in one hour increments. Logs any traffic in the current calendar week. |
| Current month |
Data is aggregated in one hour increments. Logs any traffic in the current calendar month. |
| Previous week |
Data is aggregated in one hour increments. Logs any traffic in the previous calendar week. |
| Previous month |
Data is aggregated in daily increments. Logs any traffic in the previous calendar month. |
Actions
After customizing a view using Explorer’s metrics and filters, you can perform several actions:
-
Save as a Report: This function creates a new custom report based on your current view, allowing you to revisit these specific insights at a later time.
-
Export as CSV: If you prefer to analyze your data using other tools, you can download the current view as a CSV file, making it portable and ready for further analysis elsewhere.
Diagnosing latency issues example
Explorer in Kong Konnect gives you the power to monitor your API data in detail and export that data to a CSV file.
Let’s go through an example situation where you could leverage custom reports created in Explorer. With this type of report, you can start exploring which upstream service might cause the latency spike.
One way you can build custom reports is by navigating to Analytics in the Konnect menu, then Explorer. This brings you to a page where you can control which analytics data you want to visualize. From here, configure the filter settings as follows:
-
Show: Line
-
Date/Time: Last 15 minutes
-
With: Kong Latency (p95), Upstream Latency (p95)
-
Per: Minute
Then, you can add a filter for the control plane:
-
Filter By: Control Plane
-
Choose Operator: In
-
Filter Value: prod
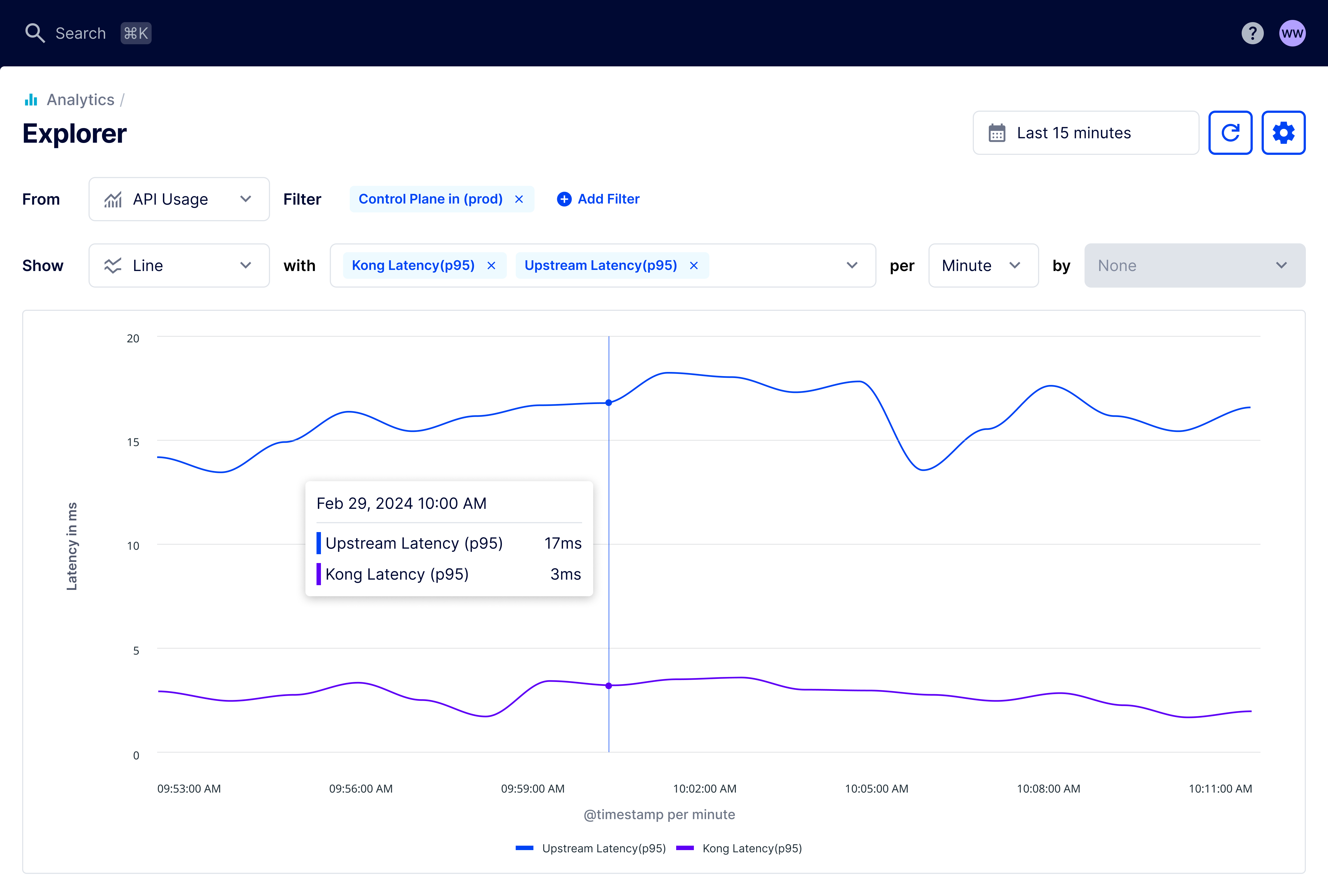
Figure 1: Line chart showing average upstream and Kong latency over the last hour.











